An entire Social Network in 1.6GB (GraphD Part 2)
In Part 1 of this series, we tried to answer the question “who do you follow who also follows user B” in Bluesky, a social network with millions of users and hundreds of millions of follow relationships.
At the conclusion of the post, we’d developed an in-memory graph store for the network that uses HashMaps and HashSets to keep track of the followers of every user and the set of users they follow, allowing bidirectional lookups, intersections, unions, and other set operations for combining social graph data.
I received some helpful feedback after that post where several people pointed me towards Roaring Bitmaps as a potential improvement on my implementation.
They were right, Roaring Bitmaps would be an excellent fit for my Graph service, GraphD, and could also provide me with a much needed way to quickly persist and load the Graph data to and from disk on startup, hopefully reducing the startup time of the service.
What are Bitmaps?
If you just want to dive into the Roaring Bitmap spec, you can read the paper here, but it might be easier to first talk about bitmaps in general.
You can think of a bitmap as a vector of one-bit values (like booleans) that let you encode a set of integer values.
For instance, say we have 10,000 users on our website and want to keep track of which users have validated their email addresses. We could do this by creating a list of the uint32 user IDs of each user, in which case if all 10,000 users have validated their emails we’re storing 10k * 32 bits = 40KB.
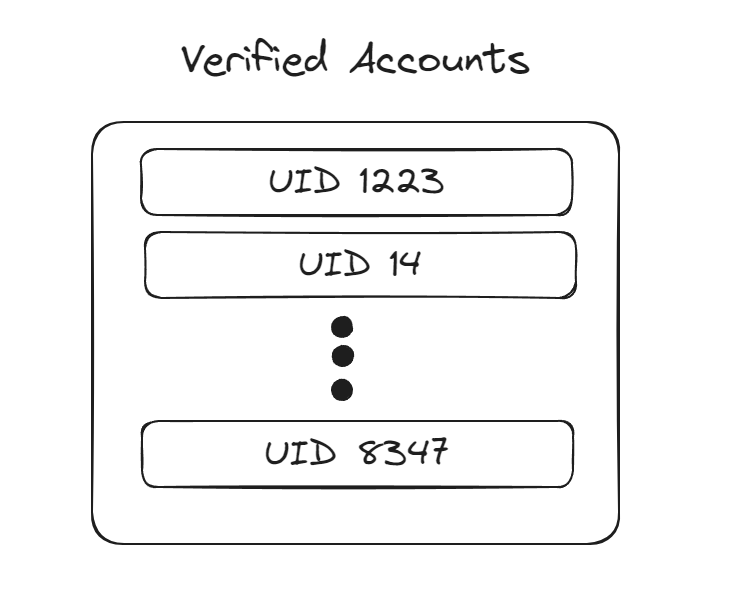
Or, we could create a vector of single-bit values that’s 10,000 bits long (10k / 8 = 1.25KB), then if a user has confirmed their email we can set the value at the index of their UID to 1.

If we want to create a list of all the UIDs of validated accounts, we can walk the vector and record the index of each non-zero bit. If we want to check if user n has validated their email, we can do a O(1) lookup in the bitmap by loading the bit at index n and checking if it’s set.
When Bitmaps get Big and Sparse
Now when talking about our social network problem, we’re dealing with a few more than 10,000 UIDs. We need to keep track of 5.5M users and whether or not the user follows or is followed by any of the other 5.5M users in the network.
To keep a bitmap of “People who follow User A”, we’re going to need 5.5M bits which would require (5.5M / 8) ~687KB of space.

If we wanted to keep bitmaps of “People who follow User A” and “People who User A follows”, we’d need ~1.37MB of space per user using a simple bitmap, meaning we’d need 5,500,000 * 1.37MB = ~7.5 Terabytes of space!
Clearly this isn’t an improvement of our strategy from Part 1, so how can we make this more efficient?
One strategy for compressing the bitmap is to take consecutive runs of 0’s or 1’s (i.e. 00001110000001) in the bitmap and turn them into a number.
For instance if we had an account that followed only the last 100 accounts in our social network, the first 5,499,900 indices in our bitmap would be 0’s and so we could represent the bitmap by saying: 5,499,900 0's, then 100 1's which you notice I’ve written here in a lot fewer than 687KB and a computer could encode using two uint32 values plus two bits (one indicator bit for the state of each run) for a total of 66 bits.
This strategy is called Run Length Encoding (RLE) and works pretty well but has a few drawbacks: mainly if your data is randomly and heavily populated, you may not have many consecutive runs (imagine a bitset where every odd bit is set and every even bit is unset). Also lookups and evaluation of the bitset requires walking the whole bitset to figure out where the index you care about lives in the compressed format.
Thankfully there’s a more clever way to compress bitmaps using a strategy called Roaring Bitmaps.
A brief description of the storage strategy for Roaring Bitmaps from the official paper is as follows:
We partition the range of 32-bit indexes ([0, n)) into chunks of 2^16 integers sharing the same 16 most significant digits. We use specialized containers to store their 16 least significant bits. When a chunk contains no more than 4096 integers, we use a sorted array of packed 16-bit integers. When there are more than 4096 integers, we use a 2^16-bit bitmap.
Thus, we have two types of containers: an array container for sparse chunks and a bitmap container for dense chunks. The 4096 threshold insures that at the level of the containers, each integer uses no more than 16 bits.
These bitmaps are designed to support both densely and sparsely distributed data and can provide high performance binary set operations (and/or/etc.) operating on the containers within two or more bitsets in parallel.
For more info on how Roaring Bitmaps work and some neat diagrams, check out this excellent primer on Roaring Bitmaps by Vikram Oberoi.
So, how does this help us build a better graph?
GraphD, Revisited with Roaring Bitmaps
Let’s get back to our GraphD Service, this time in Go instead of Rust.
For each user we can keep track of a struct with two bitmaps:
type FollowMap struct {
followingBM *roaring.Bitmap
followingLk sync.RWMutex
followersBM *roaring.Bitmap
followersLk sync.RWMutex
}
Our FollowMap gives us a Roaring Bitmap for both the set of users we follow, and the set of users who follow us.
Adding a Follow to the graph just requires we set the right bits in both user’s respective maps:
// Note I've removed locking code and error checks for brevity
func (g *Graph) addFollow(actorUID, targetUID uint32) {
actorMap, _ := g.g.Load(actorUID)
actorMap.followingBM.Add(targetUID)
targetMap, _ := g.g.Load(targetUID)
targetMap.followersBM.Add(actorUID)
}
Even better if we want to compute the intersections of two sets (i.e. the people User A follows who also follow User B) we can do so in parallel:
// Note I've removed locking code and error checks for brevity
func (g *Graph) IntersectFollowingAndFollowers(actorUID, targetUID uint32) ([]uint32, error) {
actorMap, ok := g.g.Load(actorUID)
targetMap, ok := g.g.Load(targetUID)
intersectMap := roaring.ParAnd(4, actorMap.followingBM, targetMap.followersBM)
return intersectMap.ToArray(), nil
}
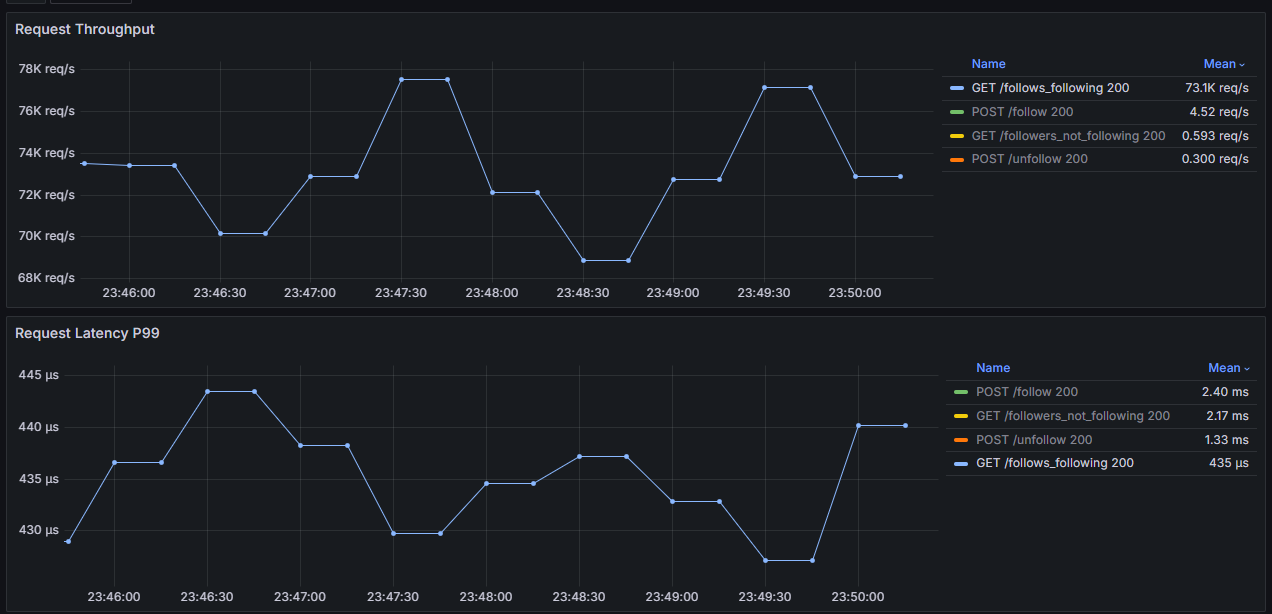
Storing the entire graph as Roaring Bitmaps in-memory costs us around 6.5GB of RAM and allows us to perform set intersections between moderately large sets (with hundreds of thousands of set bits) in under 500 microseconds while serving over 70k req/sec!
And the best part of all? We can use Roaring’s serialization format to write these bitmaps to disk or transfer them over the network.
Storing 164M Follows in 1.6GB
In the original version of GraphD, on startup the service would read a CSV file with an adjacency list of the (ActorDID, TargetDID) pairs of all follows on the network.
This required creating a CSV dump of the follows table, pausing writes to the follows table, then bringing up the service and waiting 5 minutes for it to read the CSV file, intern the DIDs as uint32 UIDs, and construct the in-memory graph.
This process is slow, pauses writes for 5 minutes, and every time our service restarts we have to do it all over again!
With Roaring Bitmaps, we’re now given an easy way to effectively serialize a version of the in-memory graph that is many times smaller than the adjacency list CSV and many times faster to load.
We can serialize the entire graph into a SQLite DB on the local machine where each row in a table contains:
(uid, DID, followers_bitmap, following_bitmap)
Loading the entire graph from this SQLite DB can be done in around ~20 seconds:
// Note I've removed locking code and error checks for brevity
rows, err := g.db.Query(`SELECT uid, did, following, followers FROM actors;`)
for rows.Next() {
var uid uint32
var did string
var followingBytes []byte
var followersBytes []byte
rows.Scan(&uid, &did, &followingBytes, &followersBytes)
followingBM := roaring.NewBitmap()
followingBM.FromBuffer(followingBytes)
followersBM := roaring.NewBitmap()
followersBM.FromBuffer(followersBytes)
followMap := &FollowMap{
followingBM: followingBM,
followersBM: followersBM,
followingLk: sync.RWMutex{},
followersLk: sync.RWMutex{},
}
g.g.Store(uid, followMap)
g.setUID(did, uid)
g.setDID(uid, did)
}
While the service is running, we can also keep track of the UIDs of actors who have added or removed a follow since the last time we saved the DB, allowing us to periodically flush changes to the on-disk SQLite only for bitmaps that have updated.
Syncing our data every 5 seconds while tailing the production firehose takes 2ms and writes an average of only ~5MB to disk per flush.
The crazy part of this is, the on-disk representation of our entire follow network is only ~1.6GB!
Because we’re making use of Roaring’s compressed serialized format, we can turn the ~6.5GB of in-memory maps into 1.6GB of on-disk data. Our largest bitmap, the followers of the bsky.app account with over 876k members, becomes ~500KB as a blob stored in SQLite.
So, to wrap up our exploration of Roaring Bitmaps for first-degree graph databases, we saw:
- A ~20% reduction in resident memory size compared to HashSets and HashMaps
- A ~84% reduction in the on-disk size of the graph compared to an adjacency list
- A ~93% reduction in startup time compared to loading from an adjacency list
- A ~66% increase in throughput of worst-case requests under load
- A ~59% reduction in p99 latency of worst-case requests under low
My next iteration on this problem will likely be to make use of DGraph’s in-memory Serialized Roaring Bitmap library that allows you to operate on fully-compressed bitmaps so there’s no need to serialize and deserialize them when reading from or writing to disk. It also probably results in significant memory savings as well!
If you’re interested in solving problems like these, take a look at our open Backend Developer Job Rec.
You can find me on Bluesky here, you can chat about this post here.