Jetstream: Shrinking the AT Proto Firehose by >99%
Bluesky recently saw a massive spike in activity in response to Brazil’s ban of Twitter.
As a result, the AT Proto event firehose provided by Bluesky’s Relay at bsky.network has increased in volume by a huge amount. The average event rate during this surge increased by ~1,300%.
Before this new surge in activity, the firehose would produce around 24 GB/day of traffic. After the surge, this volume jumped to over 232 GB/day!
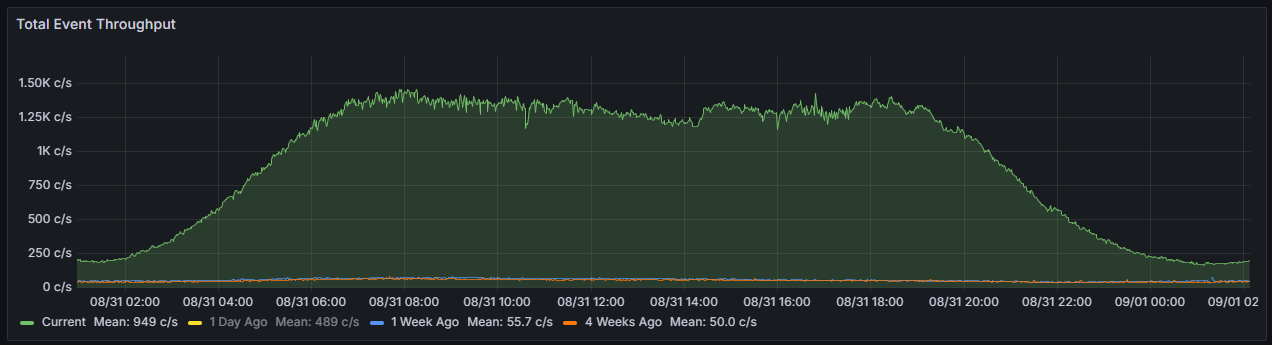
Keeping up with the full, verified firehose quickly became less practical on cheap cloud infrastructure with metered bandwidth.
To help reduce the burden of operating bots, feed generators, labelers, and other non-verifying AT Proto services, I built Jetstream as an alternative, lightweight, filterable JSON firehose for AT Proto.
How the Firehose Works
The AT Proto firehose is a mechanism used to keep verified, fully synced copies of the repos of all users.
Since repos are represented as Merkle Search Trees, each firehose event contains an update to the user’s MST which includes all the changed blocks (nodes in the path from the root to the modified leaf). The root of this path is signed by the repo owner, and a consumer can keep their copy of the repo’s MST up-to-date by applying the diff in the event.
For a more in-depth explanation of how Merkle Trees are constructed, check out this explainer.
Practically, this means that for every small JSON record added to a repo, we also send along some number of MST blocks (which are content-addressed hashes and thus very information-dense) that are mostly useful for consumers attempting to keep a fully synced, verified copy of the repo.
You can think of this as the difference between cloning a git repo v.s. just grabbing the latest version of the files without the .git folder. In this case, the firehose effectively streams the diffs for the repository with commits, signatures, and metadata, which is inherently heavier than a point-in-time checkout of the repo.
Because firehose events with repo updates are signed by the repo owner, they allow a consumer to process events from any operator without having to trust the messenger.
This is the “Authenticated” part of the Authenticated Transfer (AT) Protocol and is crucial to the correct functioning of the network.
That being said, of the hundreds of consumers of Bluesky’s production Relay, >90% of them are building feeds, bots, and other tools that don’t keep full copies of the entire network and don’t verify MST operations at all.
For these consumers, all they actually process is the JSON records created, updated, and deleted in each event.
If consumers already trust the provider to do validation on their end, they could get by with a much more lightweight data stream.
How Jetstream Works
Jetstream is a streaming service that consumes an AT Proto com.atproto.sync.subscribeRepos stream and converts it into lightweight, friendly JSON.
If you want to try it out yourself, you can connect to my public Jetstream instance and view all posts on Bluesky in realtime:
$ websocat "wss://jetstream2.us-east.bsky.network/subscribe?wantedCollections=app.bsky.feed.post"
Note: the above instance is operated by Bluesky PBC and is free to use, more instances are listed in the official repo Readme
Jetstream converts the CBOR-encoded MST blocks produced by the AT Proto firehose and translates them into JSON objects that are easier to interface with using standard tooling available in programming languages.
Since Repo MSTs only contain records in their leaf nodes, this means Jetstream can drop all of the blocks in an event except for those of the leaf nodes, typically leaving only one block per event.
In reality, this means that Jetstream’s JSON firehose is nearly 1/10 the size of the full protocol firehose for the same events, but lacks the verifiability and signatures included in the protocol-level firehose.
Jetstream events end up looking something like:
{
"did": "did:plc:eygmaihciaxprqvxpfvl6flk",
"time_us": 1725911162329308,
"type": "com",
"commit": {
"rev": "3l3qo2vutsw2b",
"type": "c",
"collection": "app.bsky.feed.like",
"rkey": "3l3qo2vuowo2b",
"record": {
"$type": "app.bsky.feed.like",
"createdAt": "2024-09-09T19:46:02.102Z",
"subject": {
"cid": "bafyreidc6sydkkbchcyg62v77wbhzvb2mvytlmsychqgwf2xojjtirmzj4",
"uri": "at://did:plc:wa7b35aakoll7hugkrjtf3xf/app.bsky.feed.post/3l3pte3p2e325"
}
},
"cid": "bafyreidwaivazkwu67xztlmuobx35hs2lnfh3kolmgfmucldvhd3sgzcqi"
}
}
Each event lets you know the DID of the repo it applies to, when it was seen by Jetstream (a time-based cursor), and up to one updated repo record as serialized JSON.
Check out this 10 second CPU profile of Jetstream serving 200k evt/sec to a local consumer:
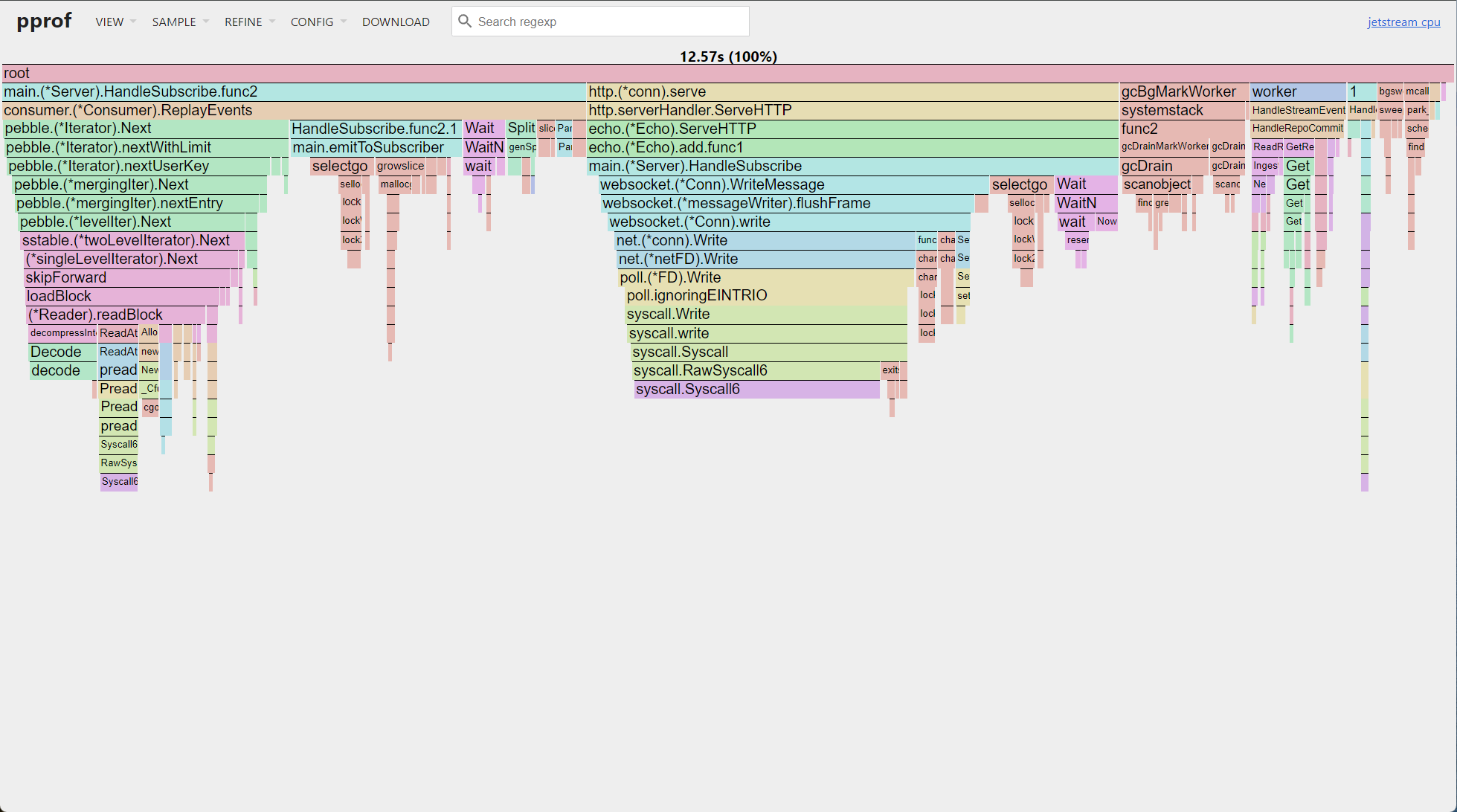
By dropping the MST and verification overhead by consuming from relay we trust, we’ve reduced the size of a firehose of all events on the network from 232 GB/day to ~41GB/day, but we can do better.
Jetstream and zstd
I recently read a great engineering blog from Discord about their use of zstd to compress websocket traffic to/from their Gateway service and client applications.
Since Jetstream emits marshalled JSON through the websocket for developer-friendliness, I figured it might be a neat idea to see if we could get further bandwidth reduction by employing zstd to compress events we send to consumers.
zstd has two basic operating modes, “simple” mode and “streaming” mode.
Streaming Compression
At first glance, streaming mode seems like it’d be a great fit. We’ve got a websocket connection with a consumer and streaming mode allows the compression to get more efficient over the lifetime of the connection.
I went and implemented a streaming compression version of Jetstream where a consumer can request compression when connecting and will get zstd compressed JSON sent as binary messages over the socket instead of plaintext.
Unfortunately, this had a massive impact on Jetstream’s server-side CPU utilization. We were effectively compressing every message once per consumer as part of their streaming session. This was not a scalable approach to offering compression on Jetstream.
Additionally, Jetstream stores a buffer of the past 24 hours (configurable) of events on disk in PebbleDB to allow consumers to replay events before getting transitioned into live-tailing mode.
Jetstream stores serialized JSON in the DB, so playback is just shuffling the bytes into the websocket without having to round-trip the data into a Go struct.
When we layer in streaming compression, playback becomes significantly more expensive because we have to compress outgoing events on-the-fly for a consumer that’s catching up.
In real numbers, this increased CPU usage of Jetstream by 23% while lowering the throughput of playback from ~200k evt/sec to ~28k evt/sec for a single local consumer.
When in streaming mode, we can’t leverage the bytes we compress for one consumer and reuse them for another consumer because zstd’s streaming context window may not be in sync between the two consumers. They haven’t received exactly the same data in the session so the clients on the other end don’t have their state machines in the same state.
Since streaming mode’s primary advantage is giving us eventually better efficiency as the encoder learns about the data, what if we just taught the encoder about the data at the start and compress each message statelessly?
Dictionary Mode
zstd offers a mechanism for initializing an encoder/decoder with pre-optimized settings by providing a dictionary trained on a sample of the data you’ll be encoding/decoding.
Using this dictionary, zstd essentially uses it’s smallest encoded representations for the most frequently seen patterns in the sample data. In our case, where we’re compressing serialized JSON with a common event shape and lots of common property names, training a dictionary on a large number of real events should allow us to represent the common elements among messages in the smallest number of bytes.
For take two of Jetstream with zstd, let’s to use a single encoder for the whole service that utilizes a custom dictionary trained on 100,000 real events.
We can use this encoder to compress every event as we see it, before persisting and emitting it to consumers. Now we end up with two copies of every event, one that’s just serialized JSON, and one that’s statelessly compressed to zstd using our dictionary.
Any consumers that want compression can have a copy of the dictionary on their end to initialize a decoder, then when we broadcast the shared compressed event, all consumers can read it without any state or context issues.
This requires the consumers and server to have a pre-shared dictionary, which is a major drawback of this implementation but good enough for our purposes.
That leaves the problem of event playback for compression-enabled clients.
An easy solution here is to just store the compressed events as well!
Since we’re only sticking the JSON records into our PebbleDB, the actual size of the 24 hour playback window is <8GB with sstable compression. If we store a copy of the JSON serialized event and a copy of the zstd compressed event, this will, at most, double our storage requirements.
Then during playback, if the consumer requests compression, we can just shuffle bytes out of the compressed version of the DB into their socket instead of having to move it through a zstd encoder.
Savings
Running with a custom dictionary, I was able to get the average Jetstream event down from 482 bytes to just 211 bytes (~0.44 compression ratio).
Jetstream allows us to live tail all posts on Bluesky as they’re posted for as little as ~850 MB/day, and we could keep up with all events moving through the firehose during the Brazil Twitter Exodus weekend for 18GB/day (down from 232GB/day).
With this scheme, Jetstream is required to compress each event only once before persisting it to disk and emitting it to connected consumers.
The CPU impact of these changes is significant in proportion to Jetstream’s incredibly light load but it’s a flat cost we pay once no matter how many consumers we have.
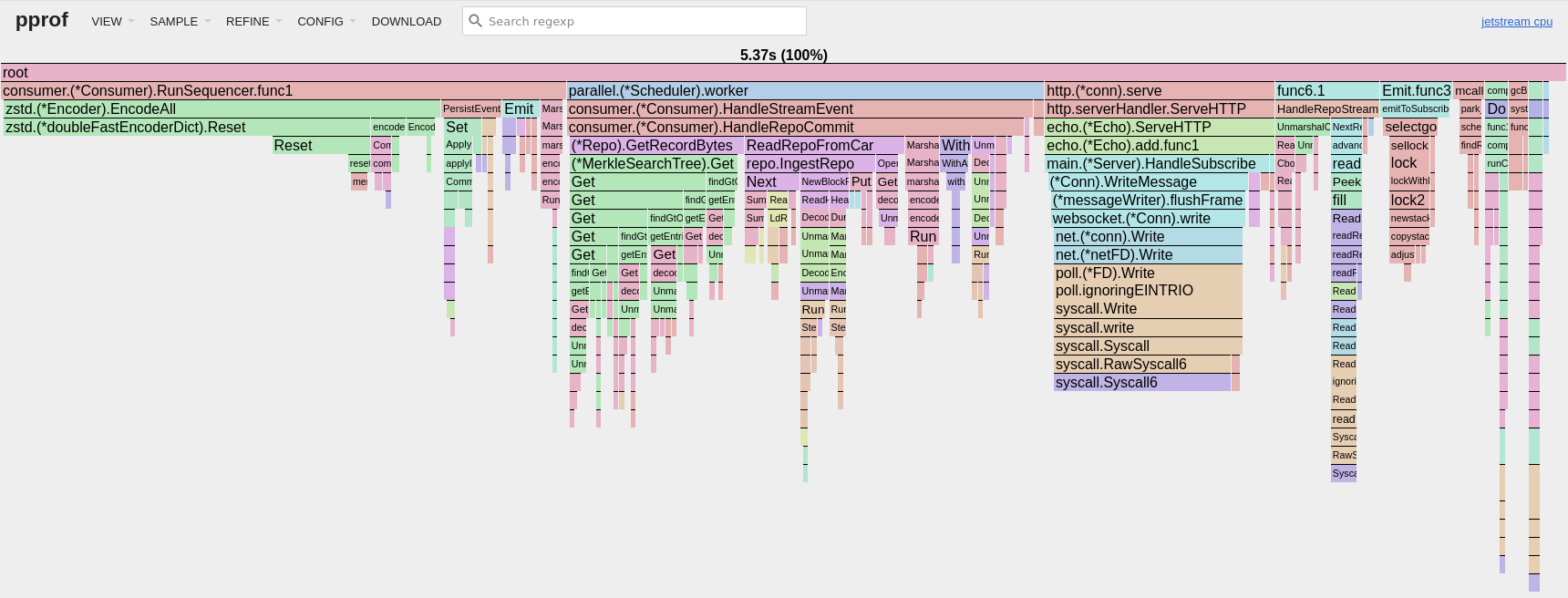
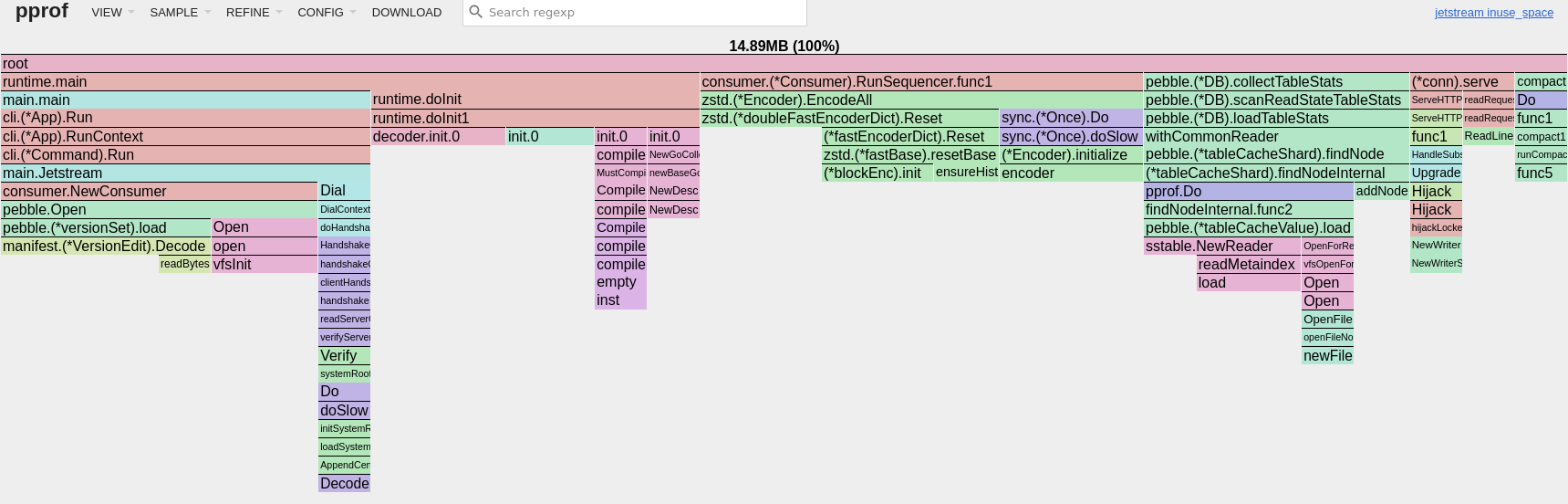
(CPU profile from a 30 second pprof sample with 12 consumers live-tailing Jetstream)
Additionally, with Jetstream’s shared buffer broadcast architecture, we keep memory allocations incredibly low and the cost per consumer on CPU and RAM is trivial. In the allocation profile below, more than 80% of the allocations are used to consume the full protocol firehose.
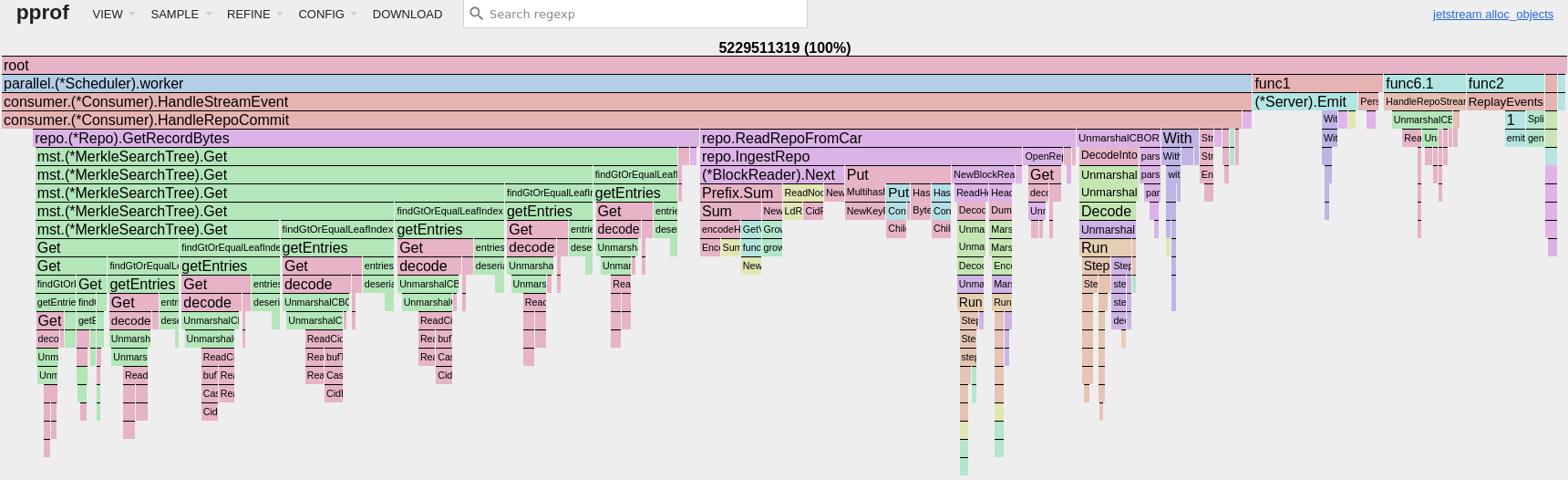
The total resident memory of Jetstream sits below 16MB, 25% of which is actually consumed by the new zstd dictionary.
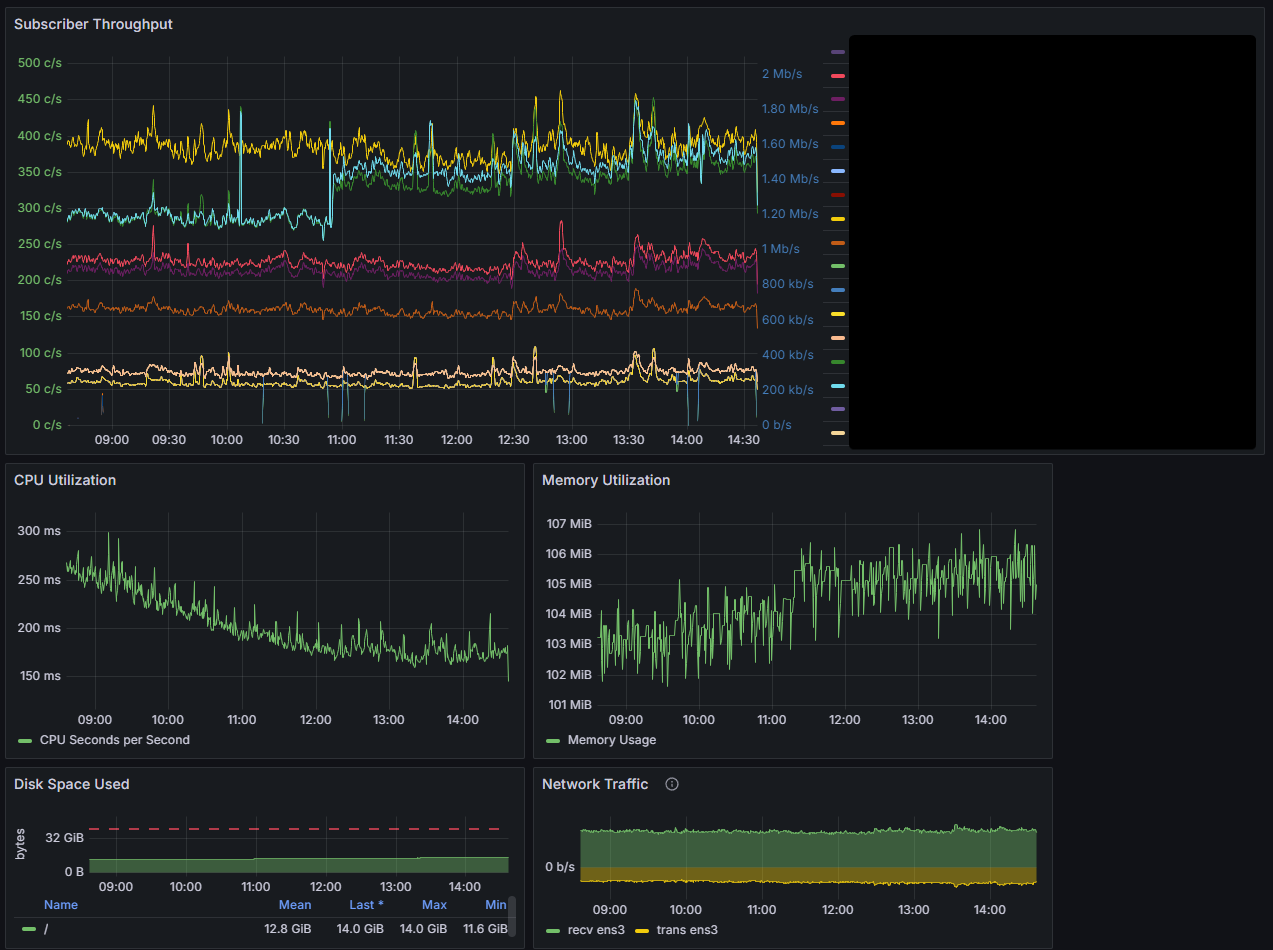
To bring it all home, here’s a screenshot from the dashboard of my public Jetstream instance serving 12 consumers all with various filters and compression settings, running on a $5/mo OVH VPS.
At our new baseline firehose activity, a consumer of the protocol-level firehose would require downloading ~3.16TB/mo to keep up.
A Jetstream consumer getting all created, updated, and deleted records without compression enabled would require downloading ~400GB/mo to keep up.
A Jetstream consumer that only cares about posts and has zstd compression enabled can get by on as little as ~25.5GB/mo, <99% of the full weight firehose.
Feel free to join the conversation about Jetstream and zstd on Bluesky.