When Imperfect Systems are Good, Actually: Bluesky's Lossy Timelines
Often when designing systems, we aim for perfection in things like consistency of data, availability, latency, and more.
The hardest part of system design is that it’s difficult (if not impossible) to design systems that have perfect consistency, perfect availability, incredibly low latency, and incredibly high throughput, all at the same time.
Instead, when we approach system design, it’s best to treat each of these properties as points on different axes that we balance to find the “right fit” for the application we’re supporting.
I recently made some major tradeoffs in the design of Bluesky’s Following Feed/Timeline to improve the performance of writes at the cost of consistency in a way that doesn’t negatively affect users but reduced P99s by over 96%.
Timeline Fanout
When you make a post on Bluesky, your post is indexed by our systems and persisted to a database where we can fetch it to hydrate and serve in API responses.
Additionally, a reference to your post is “fanned out” to your followers so they can see it in their Timelines.
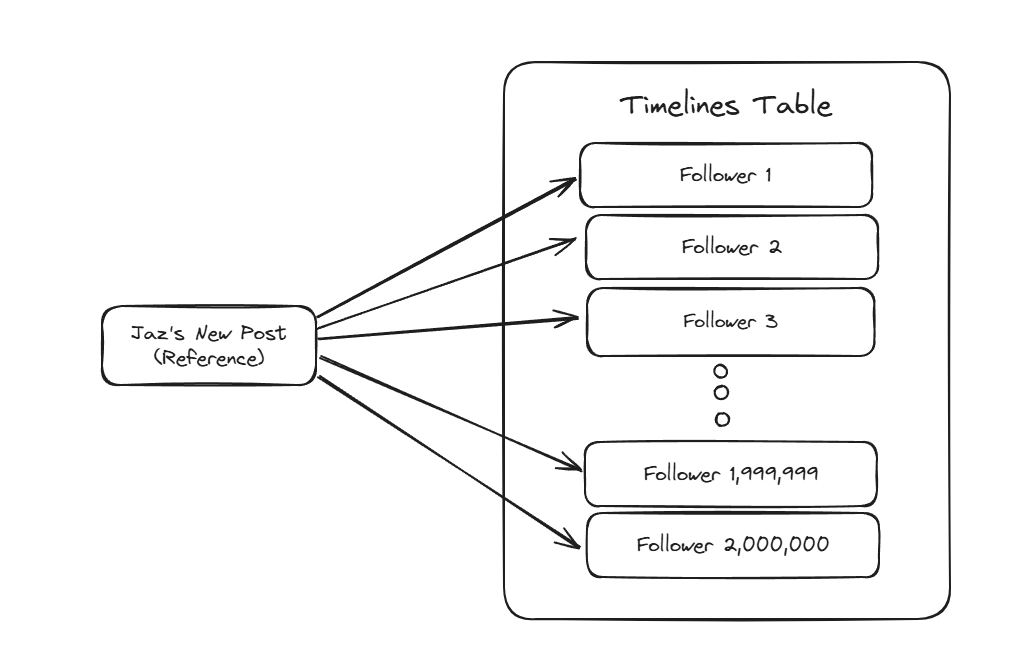
This process involves looking up all of your followers, then inserting a new row into each of their Timeline tables in reverse chronological order with a reference to your post.
When a user loads their Timeline, we fetch a page of post references and then hydrate the posts/actors concurrently to quickly build an API response and let them see the latest content from people they follow.
The Timelines table is sharded by user. This means each user gets their own Timeline partition, randomly distributed among shards of our horizontally scalable database (ScyllaDB), replicated across multiple shards for high availability.
Timelines are regularly trimmed when written to, keeping them near a target length and dropping older post references to conserve space.
Hot Shards in Your Area
Bluesky currently has around 32 Million Users and our Timelines database is broken into hundreds of shards.
To support millions of partitions on such a small number of shards, each user’s Timeline partition is colocated with tens of thousands of other users’ Timelines.
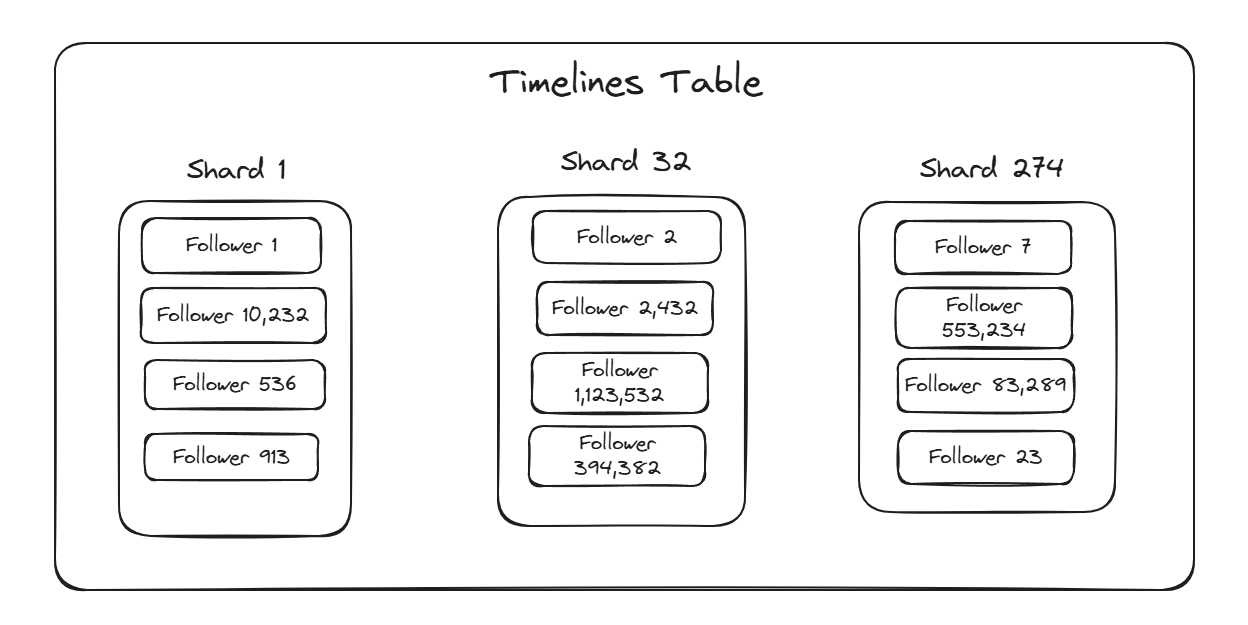
Under normal circumstances with all users behaving well, this doesn’t present a problem as the work of an individual Timeline is small enough that a shard can handle the work of tens of thousands of them without being heavily taxed.
Unfortunately, with a large number of users, some of them will do abnormal things like… well… following hundreds of thousands of other users.
Generally, this can be dealt with via policy and moderation to prevent abusive users from causing outsized load on systems, but these processes take time and can be imperfect.
When a user follows hundreds of thousands of others, their Timeline becomes hyperactive with writes and trimming occurring at massively elevated rates.
This load slows down the individual operations to the user’s Timeline, which is fine for the bad behaving user, but causes problems to the tens of thousands of other users sharing a shard with them.
We typically call this situation a “Hot Shard”: where some resident of a shard has “hot” data that is being written to or read from at much higher rates than others. Since the data on the shard is only replicated a few times, we can’t effectively leverage the horizontal scale of our database to process all this additional work.
Instead, the “Hot Shard” ends up spending so much time doing work for a single partition that operations to the colocated partitions slow down as well.
Stacking Latencies
Returning to our Fanout process, let’s consider the case of Fanout for a user followed by 2,000,000 other users.
Under normal circumstances, writing to a single Timeline takes an average of ~600 microseconds. If we sequentially write to the Timelines of our user’s followers, we’ll be sitting around for 20 minutes at best to Fanout this post.
If instead we concurrently Fanout to 1,000 Timelines at once, we can complete this Fanout job in ~1.2 seconds.
That sounds great, except it oversimplifies an important property of systems: tail latencies.
The average latency of a write is ~600 microseconds, but some writes take much less time and some take much more. In fact, the P99 latency of writes to the Timelines cluster can be as high as 15 milliseconds!
What does this mean for our Fanout? Well, if we concurrently write to 1,000 Timelines at once, statistically we’ll see 10 writes as slow as or slower than 15 milliseconds.
In the case of timelines, each “page” of followers is 10,000 users large and each “page” must be fanned out before we fetch the next page.
This means that our slowest writes will hold up the fetching and Fanout of the next page. How does this affect our expected Fanout time?
Each “page” will have ~100 writes as slow as or slower than the P99 latency. If we get unlucky, they could all stack up on a single routine and end up slowing down a single page of Fanout to 1.5 seconds.
In the worst case, for our 2,000,000 Follower celebrity, their post Fanout could end up taking as long as 5 minutes!
That’s not even considering P99.9 and P99.99 latencies which could end up being >1 second, which could leave us waiting tens of minutes for our Fanout job.
Now imagine how bad this would be for a user with 20,000,000+ Followers!
So, how do we fix the problem? By embracing imperfection, of course!
Lossy Timelines
Imagine a user who follows hundreds of thousands of others. Their Timeline is being written to hundreds of times a second, moving so fast it would be humanly impossible to keep up with the entirety of their Timeline even if it was their full-time job.
For a given user, there’s a threshold beyond which it is unreasonable for them to be able to keep up with their Timeline. Beyond this point, they likely consume content through various other feeds and do not primarily use their Following Feed.
Additionally, beyond this point, it is reasonable for us to not necessarily have a perfect chronology of everything posted by the many thousands of users they follow, but provide enough content that the Timeline always has something new.
Note in this case I’m using the term “reasonable” to loosely convey that as a social media service, there must be a limit to the amount of work we are expected to do for a single user.
What if we introduce a mechanism to reduce the correctness of a Timeline such that there is a limit to the amount of work a single Timeline can place on a DB shard.
We can assert a reasonable limit for the number of follows a user should have to have a healthy and active Timeline, then increase the “lossiness” of their Timeline the further past that limit they go.
A loss_factor can be defined as min(reasonable_limit/num_follows, 1) and can be used to probabilistically drop writes to a Timeline to prevent hot shards.
Just before writing a page in Fanout, we can generate a random float between 0 and 1, then compare it to the loss_factor of each user in the page. If the user’s loss_factor is smaller than the generated float, we filter the user out of the page and don’t write to their Timeline.
Now, users all have the same number of “follows worth” of Fanout. For example with a reasonable_limit of 2,000, a user who follows 4,000 others will have a loss_factor of 0.5 meaning half the writes to their Timeline will get dropped. For a user following 8,000 others, their loss factor of 0.25 will drop 75% of writes to their Timeline.
Thus, each user has a effective ceiling on the amount of Fanout work done for their Timeline.
By specifying the limits of reasonable user behavior and embracing imperfection for users who go beyond it, we can continue to provide service that meets the expectations of users without sacrificing scalability of the system.
Aside on Caching
We write to Timelines at a rate of more than one million times a second during the busy parts of the day. Looking up the number of follows of a given user before fanning out to them would require more than one million additional reads per second to our primary database cluster. This additional load would not be well received by our database and the additional cost wouldn’t be worth the payoff for faster Timeline Fanout.
Instead, we implemented an approach that caches high-follow accounts in a Redis sorted set, then each instance of our Fanout service loads an updated version of the set into memory every 30 seconds.
This allows us to perform lookups of follow counts for high-follow accounts millions of times per second per Fanount service instance.
By caching values which don’t need to be perfect to function correctly in this case, we can once again embrace imperfection in the system to improve performance and scalability without compromising the function of the service.
Results
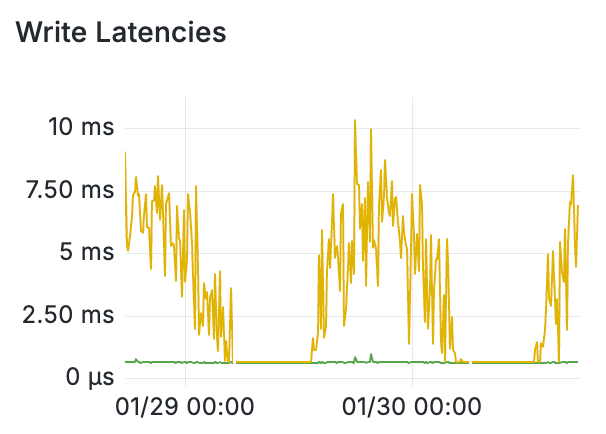
We implemented Lossy Timelines a few weeks ago on our production systems and saw a dramatic reduction in hot shards on the Timelines database clusters.
In fact, there now appear to be no hot shards in the cluster at all, and the P99 of a page of Fanout work has been reduced by over 90%.
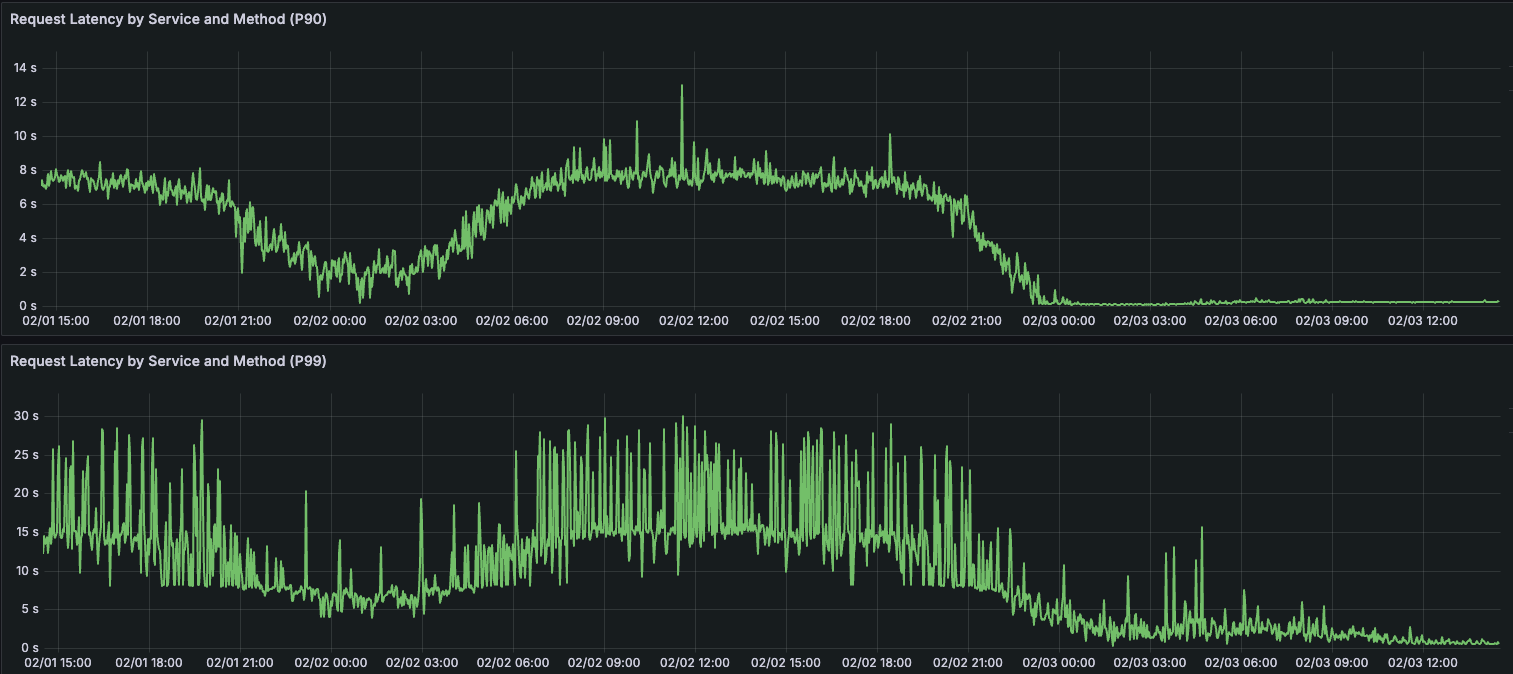
Additionally, with the reduction in write P99s, the P99 duration for a full post Fanout has been reduced by over 96%. Jobs that used to take 5-10 minutes for large accounts now take <10 seconds.
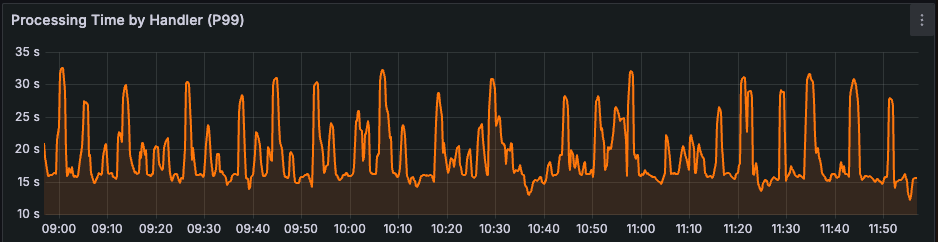
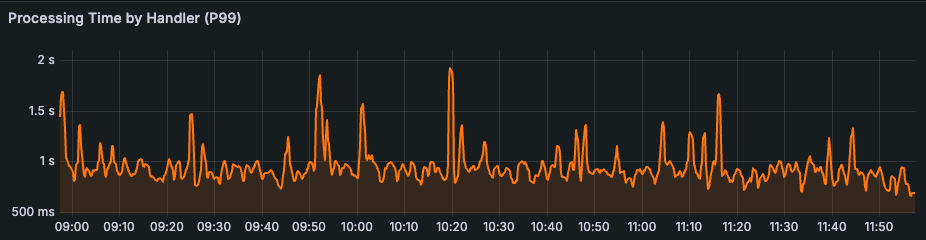
Knowing where it’s okay to be imperfect lets you trade consistency for other desirable aspects of your systems and scale ever higher.
There are plenty of other places for improvement in our Timelines architecture, but this step was a big one towards improving throughput and scalability of Bluesky’s Timelines.
If you’re interested in these sorts of problems and would like to help us build the core data services that power Bluesky, check out this job listing.
If you’re interested in other open positions at Bluesky, you can find them here.