Your Data Fits in Memory (GraphD Part 1)
I recently shipped a new revision of Bluesky’s global AppView at the start of February and things have been going very well. The system scales and handles millions of users without breaking a sweat, the ScyllaDB-backed Data Plane service sits at under 5% DB load in the most intense production workloads, and things are going great. You know what that means, time to add some new features that absolutely don’t fit the existing scalable data model!
A recent feature I’ve been working on is something we’ve referred to as “Social Proof”, the feature you see on Facebook or Twitter that shows you how many of your friends also follow this user.

The Query-time Conundrum
In our existing architecture, we handle graph lookups by paging over entire partitions of graph data (i.e. all the follows created by user A) or by looking for the existence of a specific graph relationship (i.e. does A follow B).
That’s working pretty well for things like fanning out posts someone makes to the timelines of their followers or showing that you follow the different authors of posts in a thread.
In the above examples, the “expensive” mode of loading (i.e. paging over all your follows) is done in a paginated manner or as part of an async job during timeline fanout etc.
If we want to show you “people you follow who also follow user B” when you view user B’s profile, we need a fast way to query multiple potentially large sets of data on-demand at interactive speeds.
You might recognize this feature as a Set Intersection problem:
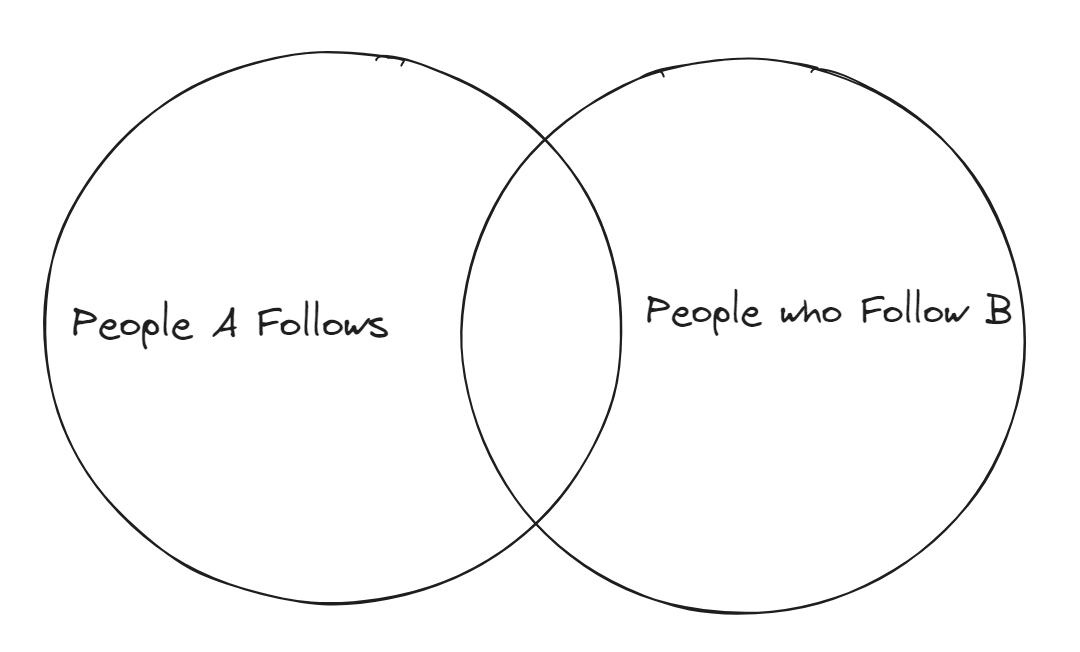
When user A views user B’s profile, we want to compute the intersection of the two sets shown in the image above to get the users that A follows who also follow user B so we can show a social proof of user B.
The easiest way to do this is to grab the list of people that User A follows from Scylla, then walk over each of those people and check if they follow user B.
We can reverse this problem and grab the list of people who follow user B and walk the list and check if user A follows them as well, but either way we’re doing a potentially large partition scan to load one of the entire sets, then potentially LOTs of one-row queries to check for the existence of specific follows.
Imagine user A follows 1,000 people and user B has 50,000 followers, that’s one expensive query and then 1,000 tiny queries every time we hydrate User B’s profile for user A and those queries will be different for every user combination we need to load.
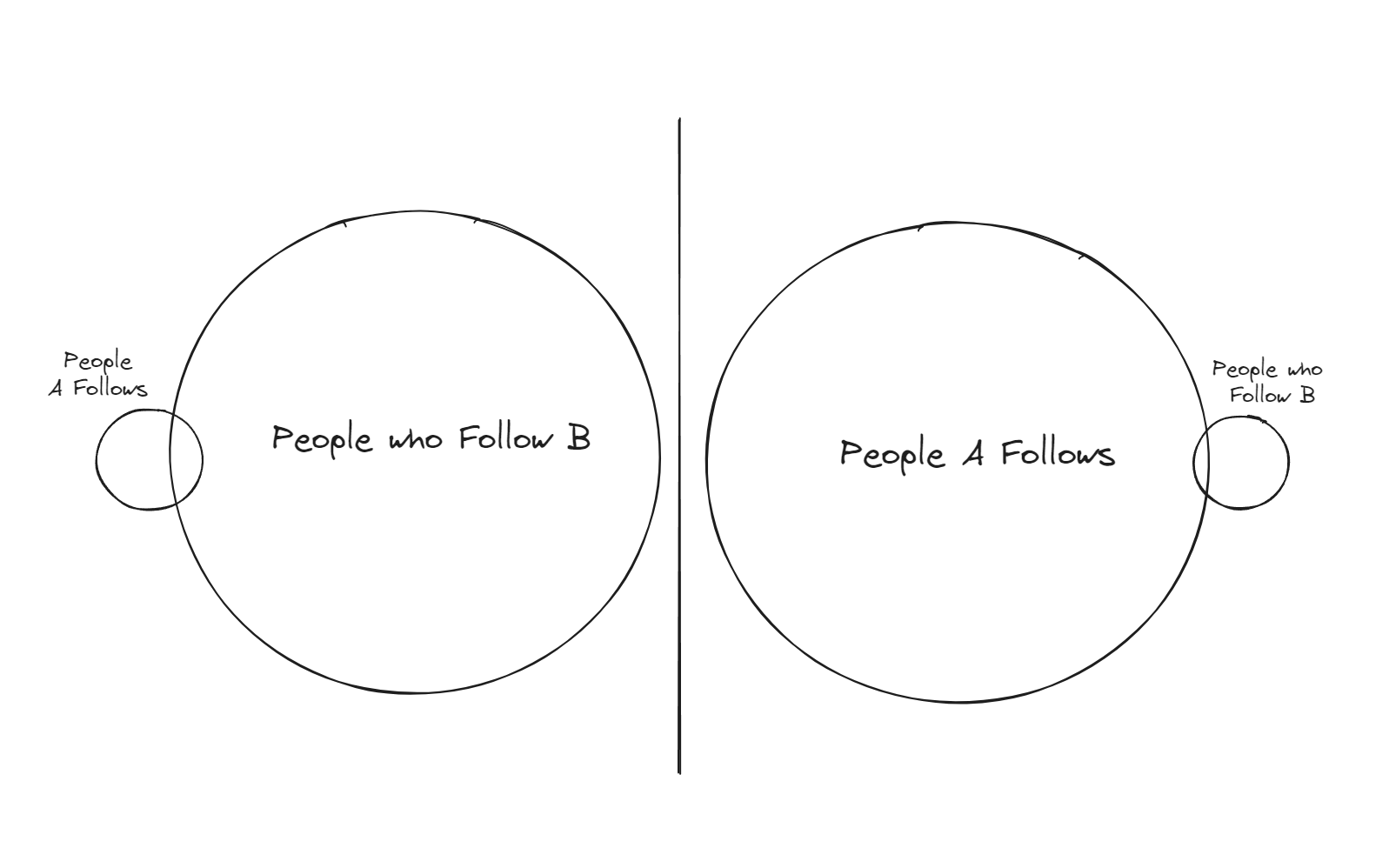
A more efficient way to tackle this problem would be to load both sets (A’s follows and followers of B) and then intersect them in-memory in our service.
If we store both sets in-memory as Hash Maps we can iterate over the smaller set and perform fast lookups for membership in the other set. Some programming languages (i.e. rust) even have Set data structures that natively support efficient intersection methods.
But can we even fit this data in memory?
How Much Memory does a Graph Take?
In our network, each user is assigned a DID that looks something like did:plc:q6gjnaw2blty4crticxkmujt which you might notice is a 32 character string. Not all DIDs are this long, they can be longer or shorter but the vast majority (>99.9%) of DIDs on AT Proto are 32 character strings.
The AT Proto network currently has ~160M follow records for ~5.5M users. If we were to store each of these follows in a pair of HashMaps (one to lookup by the actor, one to lookup by the subject) how much memory would we need?
Keys: 32 Bytes * 5.5M Users * 2 Maps = ~352MB
Values: 160M Follows * 32 Bytes * 2 Maps = ~10.24GB
Just the raw keys and values total around 10.5GB with some wiggle room for HashMap provisioning overhead we’re looking at something like 12-14GB of RAM to store the follow graph. With modern computers that’s actually not too crazy and could fit in-memory on a production server no problem, but we can do one step better.
If we convert each DID into a uint64 (a process referred to as “interning”), we can significantly compress the size of our graph and make it faster since our hashing functions will have fewer bytes they need to work with.
UID-Lookup-Maps: (32 Bytes * 5.5M Users) + (8 Bytes * 5.5M Users) = 177MB + 44MB = ~221MB
Keys: 8 Bytes * 5.5M Users * 2 Maps = 88MB
Values: 160M Follows * 8 Bytes * 2 Maps = ~2.56GB
Our new in-memory graph math works out to under 3GB, maybe closer to 4-5 GB including provisioning overhead. This looks even more achievable for our service!
How Fast is it?
To prove this concept can power production-scale features, I built an implementation in Rust that loads a CSV adjacency list of follows on startup and provides HTTP endpoints for adding new follows, unfollowing, and a few different kinds of queries.
The main structure of the graph is quite simple:
pub struct Graph {
follows: RwLock<HashMap<u64, HashSet<u64>>>,
followers: RwLock<HashMap<u64, HashSet<u64>>>,
uid_to_did: RwLock<HashMap<u64, String>>,
did_to_uid: RwLock<HashMap<String, u64>>,
next_uid: RwLock<u64>,
pending_queue: RwLock<Vec<QueueItem>>,
pub is_loaded: RwLock<bool>,
}
We keep track of follows in two directions, from the actor side and from the subject side. Additionally we provide two lookup maps, one that turns DIDs to u64s and one that turns u64s back into DIDs.
Finally we keep a variable to know which ID we will assign to the next DID we learn about, and two variables that enqueue follows while we’re loading our graph from the CSV so we don’t drop any events in the meantime.
To perform our Social Proof check, we can make use of this function:
// `get_following` and `get_followers` simply acquire a read lock
// on their respective sets and return a copy of the HashSet
pub fn intersect_following_and_followers(&self, actor: u64, target: u64) -> HashSet<u64> {
self.get_following(actor)
.intersection(&self.get_followers(target))
.cloned()
.collect()
}
To test the validity of this solution, we can use K6 to execute millions of semi-random requests against the service locally.
For this service, we want to test a worst-case scenario to prove it’ll hold up, so we will intersect the following set of many random users against the 500 largest follower accounts on the network.
Running this test over the course of an hour at a rate of ~41.5k req/sec we see the following results:
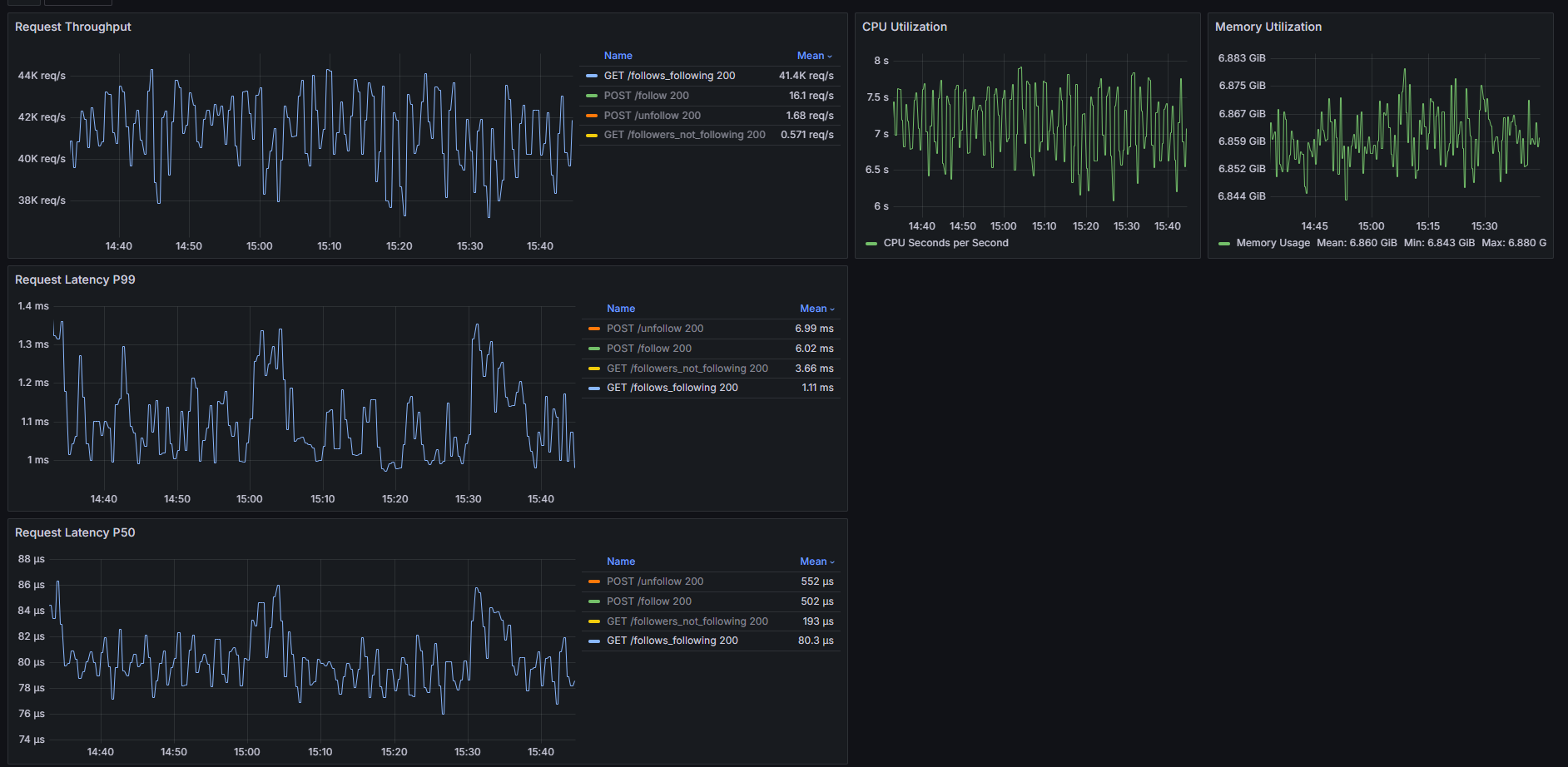
We’re consuming ~6.6GB of resident RAM to support the graph and request load, and our service is responding to these worst-case requests with a p99 latency of ~1.2ms while keeping up with writes from the event firehose and utilizing around 7.5 CPU cores.
Compared to a solution that depends on Redis sets, we’re able to utilize multiple CPU cores to handle requests since we leverage RWLocks that don’t force sequential access for reads.
The best part is, we don’t need to hit our Scylla database at all in order to answer these queries!
We don’t need expensive concurrent fanout or to hammer Scylla partitions to keep fresh follow data in sync to perform set intersections.
We can backfill and then iteratively maintain our follow graph in-memory for the cost of a little bit of startup time (~5 minutes) and a few GB of RAM. Since it’s so cheap, we could even run a couple instances of the service for higher availability and rolling updates.
After this proof of concept, I went back and performed a more realistic sustained load test at 2.65k req/sec for 5 hours to see what memory usage and CPU usage look like over time.
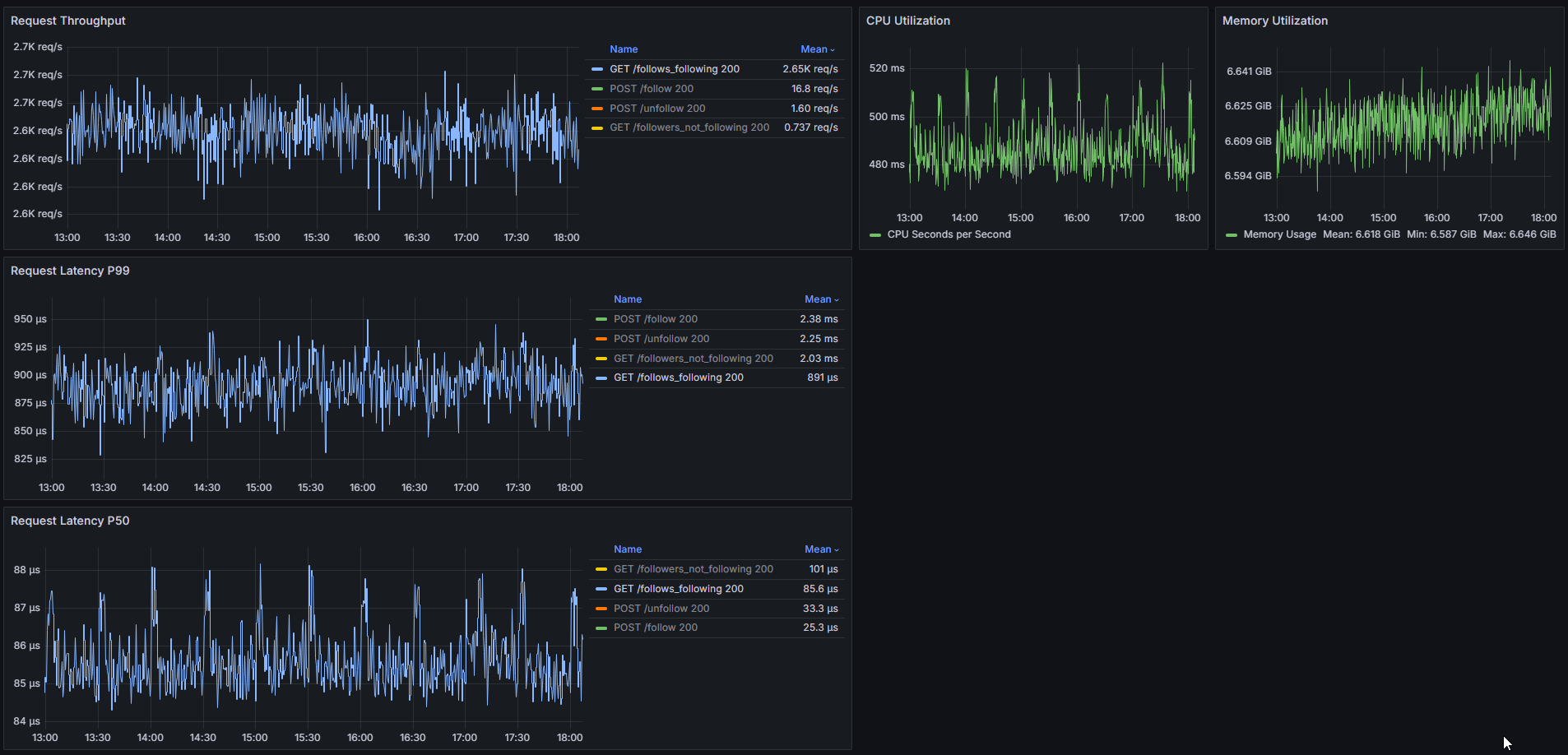
Under a realistic throughput (but worst-case query) production load we keep p99s of under 1ms and consume 0.5 CPU cores while memory utilization trends slowly upward with the growth of the follow graph (+16MiB over 5 hours).
There’s further optimization left to be made by locking individual HashSets instead of the entire follows or following set, but we can leave that for a later day.
If you’re interested in solving problems like these, take a look at our open Backend Developer Job Rec.