Turning Billions of Strings into Integers Every Second Without Collisions
I’ve recently started building a POC of a Redis RESP3 Wire Compatible Key/Value Database built on FoundationDB with @calabro.io and though it’s rather early, it’s already spawned a fun distributed systems problem that I thought would be interesting to share.
Previously I’ve written about how I implemented a Graph DB via Roaring Bitmaps, representing relations as a bidirectional pair of sets.
To support such use-cases in this new database, we’d like to represent sets of keys such that you can perform boolean operations on them (intersection, union, difference) relatively quickly even for very large sets (with millions of members).
Supporting Larger Keys
In the original Graph DB, we were representing user DID strings as uint32 UIDs to allow us to store millions of edge lists in very little space (e.g. the set of users who follow bsky.app) while being able to perform boolean operations between lists quickly (using Roaring Bitmaps’ parallel boolean operators).
Since we were graphing follows, blocks, and other such User-to-User relationships, there was a practical maximum for the total number of user IDs in the low billions.
We’ve continued exploring objects and relationships we’d like to represent as a Graph, and have realized that if we wanted to store e.g. the URIs of all posts a user has liked so we can intersect it with other users’ likes, we’re going to need a bigger keyspace!
There are well over 15 Billion records in the AT Proto Ecosystem, each with a unique AT URI!
Now our desired keyspace is much larger than can be represented by uint32 values and so we need to expand to uint64.
Easy enough, let’s use the uint64 flavor of Roaring Bitmaps and simply intern URIs and User DIDs as uint64s, problem solved, right?
Not quite…
Interning Many Things at Once
The AT Proto Firehose has hit historic peak traffic of over 1,500 evt/sec.
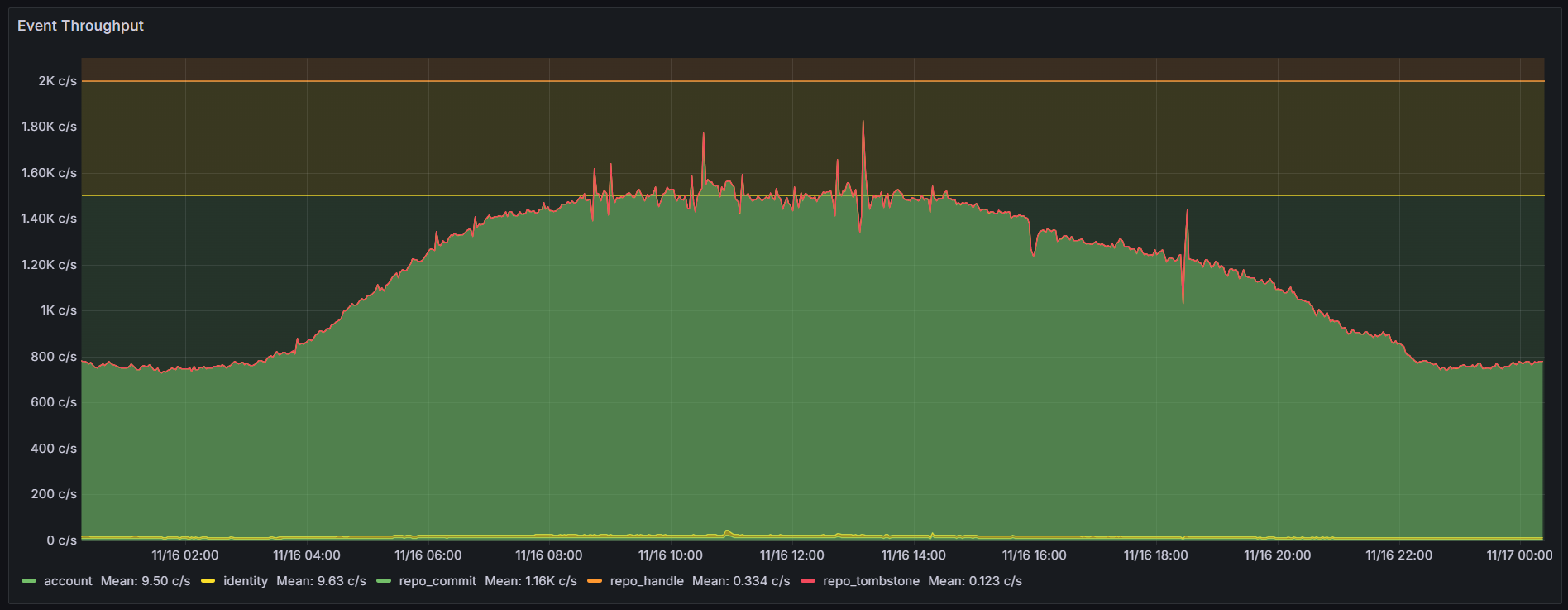
We want to design a system that will handle many times more scale than we’ve ever seen in reality.
This means designing for 10x or 100x would require us to be able to intern 15k to 150k new URIs per second into uint64 integers.
Sounds easy enough, what’s the holdup?
Well, in FoundationDB we’re able to use Transactions to do things like atomically increment a sequence safely when many other threads may be trying to do the same thing.
This is simple enough to do in Go, we can just toss together a little helper function to acquire a new UID for our string:
func (s *server) allocateNewUID(span trace.Span, tx fdb.Transaction) (uint64, error) {
var newUID uint64
val, err := tx.Get(fdb.Key("last_uid")).Get()
if err != nil {
return 0, return fmt.Errorf("failed to get last UID: %w", err)
}
if len(val) == 0 {
newUID = 1 // start from 1
} else {
lastUID, err := strconv.ParseUint(string(val), 10, 64)
if err != nil {
return 0, return fmt.Errorf("failed to parse last UID: %w", err)
}
newUID = lastUID + 1
}
tx.Set(fdb.Key("last_uid"), []byte(strconv.FormatUint(newUID, 10)))
return newUID, nil
}
This function gets called from a fdb.Transaction which gets assigned a Transaction ID, then stages its changes, then tries to commit them.
In FoundationDB, if your transaction is reading or modifying data written to by a different Transaction that finishes while you’re in-progress, your Transaction is thrown out and must be retried.
For our UID assignment use-case, this is pretty problematic. We want to assign hundreds of thousands of new UIDs per second but if they’re all modifying the same key, concurrent transactions will constantly run into contention on the same data and will be forced to retry over and over again. This problem gets worse the more concurrent transactions you have trying to read from or write to the same key.
Even if we stick to sequential access, if it takes ~5-10ms to assign a UID, we can only assign ~100-200 UIDs per second, nowhere near the throughput we need to support.
How can we get past this problem and allow us to give strings unique uint64 UIDs in a high throughput and highly concurrent manner?
Attempt #1: xxHash
My first attempt to solve this problem was to try something that required no coordination and hash the string keys into uint64s using xxHash.
xxHash is a non-cryptographic hash algorithm that supports incredibly high throughput (dozens of GB/sec) and can produce 64 bit unsigned integer hashes of strings trivially.
Implementing this would look something like:
- Hash the incoming string key
- Lookup the
uint64UID to see if we’ve already assigned it to a string- Reject the transaction if there’s a collision and give up
- Store the key in the UID map and the UID in the key map
- Use the UID for anything else we need
While the uint64 keyspace is plenty large for our needs assuming we distribute evenly among the whole space, using a hashing algorithm with no coordination means there’s room for collisions and thus we’d need some additional logic (potentially by bucketing the keys somehow).
Consulting the Birthday Problem we can see that a keyspace with 64 bit hashes has a >50% chance of containing a single collision when we have only ~5 billion keys in the set! That’s barely more keys than we can cram into a uint32 and definitely won’t suffice for the number of keys we expect to be storing!
So, xxHash, while nice and coordination-free is probably not going to be the solution we need.
What else can we do?
Attempt #2: Billions of Sequences
Incrementing one sequence is clearly not an option because we can only increment a single sequence ~100-200 times per second, but what if we instead had more than one sequence?
Roaring Bitmaps managed to make highly efficient bitmap representations by breaking up a uint32 keyspace into a uint16-wide set of uint16-wide keyspaces. Can we do something similar here?
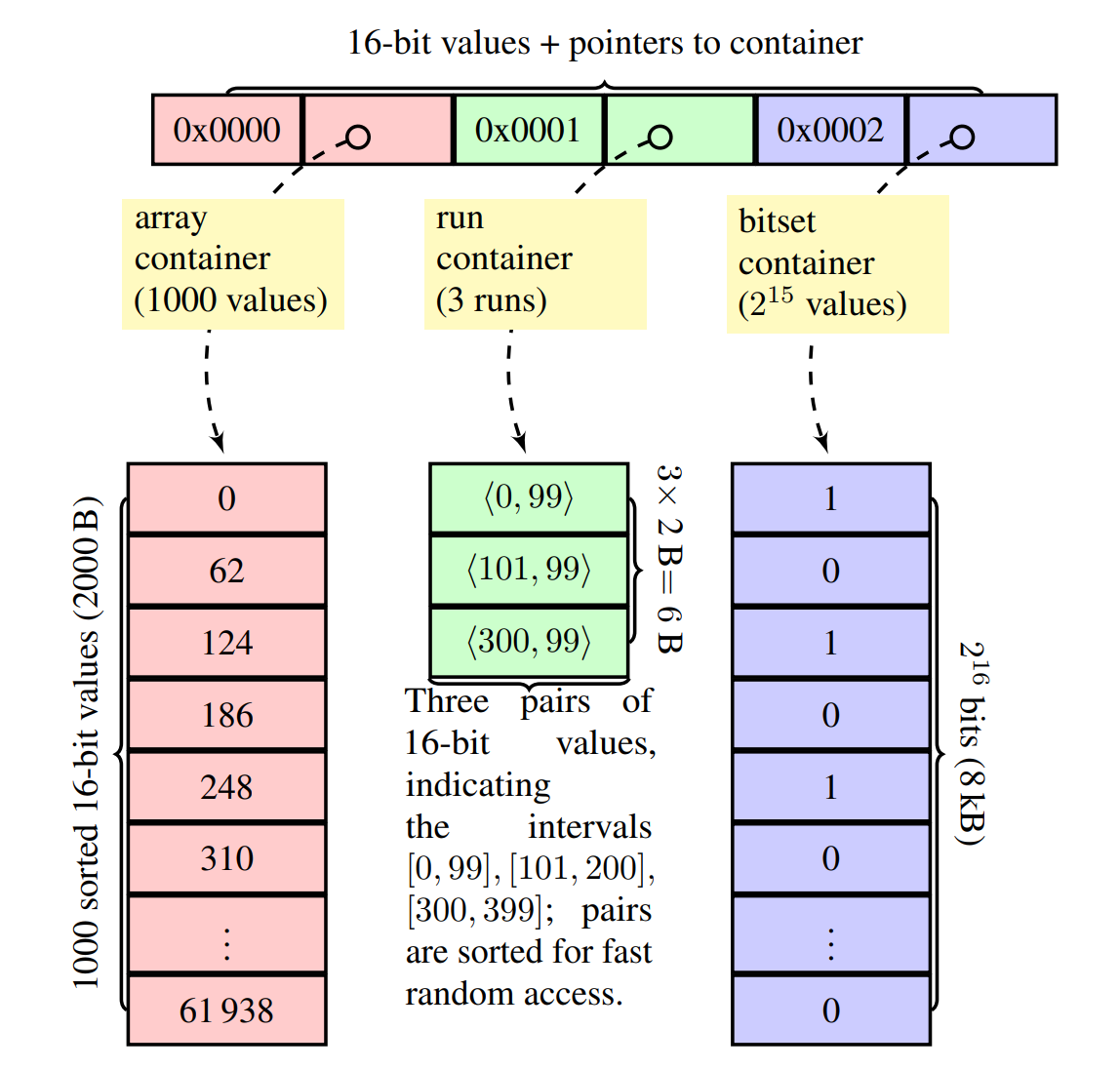
Here’s an idea, what if we had just over 4 billion difference sequences and just picked one at random when we needed to assign a UID?
Since we’re constructing our UIDs as a uint64, we can split the full UID into a pair of uint32s where the most-significant-bits are used to identify the sequence ID and the least-significant-bits are used to identify the value assigned to the UID within the sequence.
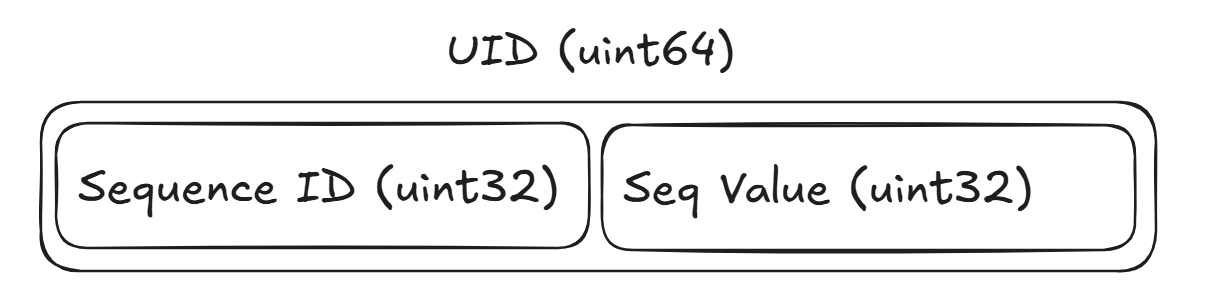
So in our implementation, we get ~4.3 Billion sequence IDs that each have ~4.3 Billion incrementing values.
As an example, if we were to randomly select Sequence ID 37 and then we increment that sequence to the value 5, we’d assemble the ID as 37<<32 + 5 which looks like 158,913,789,952 + 5 -> 158,913,789,957. Looking at the next Seuqence ID, we’d see 38 which, when left shifted by 32 gives us 163,208,757,248. You can see there’s a gap of ~4.3 billion values between the first UID assigned by each Sequence ID.
Assuming we can increment a single sequence ~100 times per second with contention, we’re able to mint 430 Billion new UIDs per second without locking up (assuming the cluster can keep up).
Storing ~4.3 billion sequences may be a bit expensive, but thankfully this strategy can scale up and down by picking a larger or smaller prefix size. If we only wanted to store say, ~16k sequences, we can pick a 14 bit prefix instead of a 32 bit prefix and then use a 50 bit sequence number. That spreads the load across 2^14 sequence IDs and significantly reduces storage requirements for Sequences.
What does this look like in code? Well, it’s honestly not very complex!
const uidSequencePrefix = "uid_sequence/"
func (s *server) allocateNewUID(tx fdb.Transaction) (uint64, error) {
// sequenceNum is the random uint32 sequence we are using for this allocation
var sequenceNum uint32
var sequenceKey string
// assignedUID is the uint32 within the sequence we will assign
var assignedUID uint32
// Try up to 5 times to find a sequence that is not exhausted
for range 5 {
// Pick a random uint32 as the sequence we will be using for this UID
sequenceNum = rand.Uint32()
sequenceKey = fmt.Sprintf("%s%d", uidSequencePrefix, sequenceNum)
val, err := tx.Get(fdb.Key(sequenceKey)).Get()
if err != nil {
return 0, fmt.Errorf("failed to get last UID: %w", err)
}
if len(val) == 0 {
assignedUID = 1 // Start each sequence at 1
} else {
lastUID, err := strconv.ParseUint(string(val), 10, 32)
if err != nil {
return 0, fmt.Errorf("failed to parse last UID: %w", err)
}
// If we have exhausted this sequence, pick a new random sequence
if lastUID >= 0xFFFFFFFF {
continue
}
assignedUID = uint32(lastUID) + 1
}
}
// If we failed to find a sequence after 5 tries, return an error
if assignedUID == 0 {
return 0, fmt.Errorf("failed to allocate new UID after 5 attempts")
}
// Assemble the 64-bit UID from the sequence ID and assigned UID
newUID := (uint64(sequenceNum) << 32) | uint64(assignedUID)
// Store the assigned UID back to the sequence key for the next allocation
tx.Set(fdb.Key(sequenceKey), []byte(strconv.FormatUint(uint64(assignedUID), 10)))
// Return the full 64-bit UID
return newUID, nil
}
And there we go! We can now intern billions of strings per second with little to no contention in a distributed system while completely avoiding collisions and making full use of our keyspace!
Conclusion
Often times when designing distributed systems, patterns and strategies you see in seemingly unrelated libraries can inspire an elegant solution to the problem at hand.
In the case of distributed, high-throughput string interning, horizontal scaling can be achieved by breaking up one large keyspace that requires strict coordination into billions of smaller keyspaces that can be randomly load-balanced across.
Both patterns used in this technique are present elsewhere:
- Breaking up a large keyspace into a bunch of smaller keyspaces is present in Roaring Bitmaps (among other systems)
- Letting randomness and large numbers spread out resource contention is present in many load balancing systems
This is one of my favorite parts of growing as an engineer: the more systems and strategies you familiarize yourself with, the more material you have to draw from when designing something new.
Personal News
A bit of personal news for y’all if you made it this far.
Today is my last day as a member of the Bluesky team!
The past 2+ years building out Bluesky’s Infrastructure and Platform team and scaling Bluesky from 100,000 -> 40,000,000 users have been the most intense and rewarding years of my life.
I don’t have the words to express how much I’ve valued my time on the team and how much I care for the people I’ve worked with in what feels like a decade of real time.
I’ve got some new adventures ahead and am excited to be embarking on a new journey within the next month (still building large-scale infrastructure, don’t worry).
I plan to continue being involved in the AT Proto Community and to contribute to some cool projects other folks on the Bluesky team are working on from the FOSS space (like KVDB).
To the team, I wish you all the best and will dearly miss getting to work with you all every day, but nothing lasts forever and I will always cherish the time I got to spend building an incredible platform with incredible people.
If you’re interested in joining a world-class team doing important work, check out Bluesky’s open job listings here.
There should be a new role opening up for a seasoned Go Engineer on the Platform team soon!